Creating a new kind of search tool is not a simple task. Most search
engines are very similar to each other. The user interface is usually a
field where the user can input keywords and in some cases fields for specifying
the search a bit more. Using the input from the user, the search engine
ranks the hits and presents them to the user. If the search tool is a directory,
the user can either navigate through the hierarchy or do a text search
in all or parts of the hierarchy, and the hits are listed as they are found
in the hierarchy. None of these search tools offer much direct support
in the search process, apart from supplying the search index/hierarchy.
We must do better.
If we let a denote relevant retrieved elements from the total information space, b nonrelevant retrieved elements and c relevant elements not retrieved, recall is defined as a/(a+c), and precision as a/(a+b).
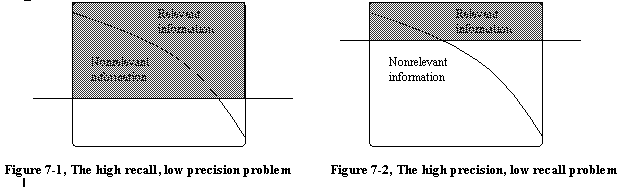
In Figure 7-1 a broad search query has resulted in high recall, meaning that a lot of the relevant information available (the top triangle of the square) is returned, but low precision, meaning that a lot of the nonrelevant information is also returned by the search. In Figure 7-2, a narrow search query result, the precision is high, just a little nonrelevant information is returned, but the recall is low, with most of the relevant information not returned by the search.
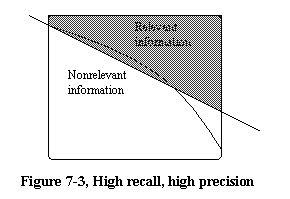
In general we may say that search engines, depending on how they are used, suffer from both of these problems, while directories mainly have the high precision and low recall-problem, depending on how much of all available information on a topic that actually can be found in the directory. We want to create a search tool that refines the users search, making the search definition less rigid without turning user-unfriendly, until as much of the relevant information as possible and very little nonrelevant information is returned, as shown in Figure 7-3. In addition, the returned information should be presented ranked in an order decided by the user, instead of in an order assumed interesting to the user by the search tool.
These ways of classifying searching can be shown in a two-dimensional
grid, where our users need to be supported in different ways in the four
main ways of searching:
| Novice Users | Expert Users | |
| Navigate | The hierarchy must be easy to browse, with good explanations on how
to move in it and on what information the different parts of the hierarchy
contain. The screen must not contain so much information that the user
is over-whelmed.
|
Less information on how to use the system is required, so more actual hierarchy information can be on-screen at any time. Classification codes can be used to a larger extent, instead of explanations. |
| Query | The user must be guided through the various options for refining the search in all different ways offered by the system. It must be ensured that the hits are ranked the way the user actually wants them to be ranked, and explanations on what criteria each hit matched must be available. | Instead of guiding the user from step to step, queries can be done through forms, where the expert user uses the fields necessary to perform the search. Boolean expressions can be used to formulate the queries. |
It must be easy to see information about what area of the hierarchy you are in at any time. In addition to looking at what can be found in that area, it is necessary to show what can be found by moving one level up or down in the hierarchy.
While navigating in the hierarchy, the users must be able to toggle between only seeing the topic headings and seeing the actual entries that are indexed under the various topics. At any time, when having found a topic that is of interest to the user, it should be possible for the user to navigate among the Web pages along other dimensions, for example by page class, language, ratings or graphics use. Changing what dimension to navigate along can be done at any time, and if it is done systematically, it can be used to efficiently narrow down the range of pages to navigate between. The downside of this is that for document properties that are not required but optional for the indexing, this means that pages without a value for that particular property will not be found through hierarchy navigation.
When the number of pages within the navigation space is reduced to a
relatively small number, an interesting option may be to retrieve the first
few lines of text from these pages for the user to view, to help the user
in deciding what page to go to. If a Web page has been given several codes
for Dewey classification and/or page class, it should be possible to move
directly to the other area(s) of the hierarchy where the page also can
be found indexed.
The differences between navigating using the EDDIC system and a traditional directory like Yahoo! are the same for both novice and expert navigation:
In [Shneiderman, 1997] a four-phase framework for coordinating design of general search/query processes is mentioned. It aims to reduce user frustration and confusion while supporting the search process. Adapted to our use, this is what it looks like:
1. Formulation, expressing the search
The search support we introduce is the webrarian, an interface agent capable of getting to know the users. The webrarian will communicate with the user, guiding the user to pages that match the users needs. Since we have a systematically built index equipped with a vocabulary, we want to use this to simplify the communication.
Although we introduce the webrarian as an assistant to the user, we do not want our agent to pretend to be human. To be even more specific, neither do we want it to appear to be intelligent. This means we must be very careful when visualizing the webrarian. The users should think of the webrarian as an assistant with a very limited ability to understand human behavior. The only thing the webrarian is capable of is guiding people to the right spot in the index. Similarly, the choice of words in the communication with the user should not let on that the agent is something else than a mindless, narrow-minded webrarian.
The search process must be quick, so we do not have time for any heavy natural language processing. The users written input should be limited to a very short typed input initially. Throughout the rest of the search the agent-human dialog should take place as questions from the agent, to which the user answers by picking the one of a few agent-generated responses that best matches the users desires. When the webrarian has enough information to narrow the search down to a certain number of matching Web pages, the list of hits should appear on the screen. Then the user will have to decide whether to start browsing the hits, or to continue answering questions from the webrarian to further refine the search. The certain number should be adjustable by the user, but per default be set to a relatively low number. This is to avoid the kind of situation that often takes place with the search engines of today, where a user gives the search engine one or more keywords, and the search engine enthusiastically claims to have found hundreds of thousands of matching documents and overwhelms the user.
A preliminary user interface is shown in Figure 7-4. Following [Shneiderman]s framework, the Formulation phase is covered by the upper part of the window. The webrarian is depicted as some kind of expressionless agent asking questions. The system generates reponses it is capable of handling and offers them to the user in the top left area of the window. The user, who supplies a keyword, initiates the search. The agent compares this keyword with its knowledge base, the EDDIC classification codes and the index entries, and generates questions to narrow down the search scope based on this.
The second phase, Action, starts when the webrarian has narrowed the search down so much that the number of matching documents from the index is small enough that it is practical to start showing them. From then on, the Formulation and Action phases will both be active. Each time the user responds to a new question from the agent, the hit list is immediately updated. The user decides when to stop answering questions and start browsing the hits instead.
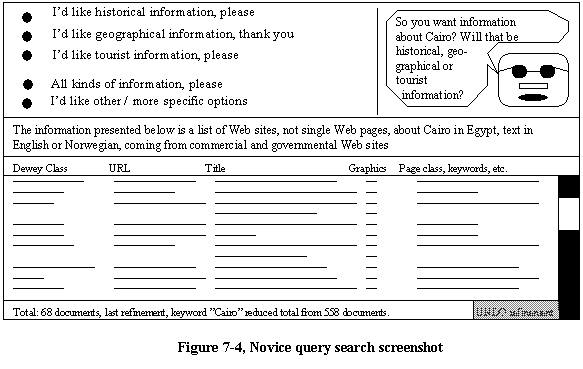
The Review phase is covered by the lower part of the window. Just below the upper area of the window there is a field explaining what the information listed below is based on. This is basically just a review of what answers the user has given to the webrarians questions. The main area of the window is the listing, in the figure depicted as lines of various lengths, of Web pages matching the users desires. The list has headers explaining what the listing fields are. This part of the window contains a scrollbar, since it will often contain more information than can be fitted on one screen. By clicking on one of these fields it should be possible to decide how the pages on the list are ranked, with the presumed most interesting pages moved to the top of the list. This kind of explanation for how the webrarian has decided to list exactly these pages, makes it easier for the user to trust the system. According to [Lieberman, 1997], if the user perceives the agents actions as actions that I could have done myself, the user is more willing to conceptualize the agent in the role of an assistant.
On the bottom of the page there is information about the search, telling how many documents that presently match the user input, as well as how many documents that matched the user input before the most recent refining question was answered. There is also a button to press to go back one step in the search process. This, together with the questions generated by the agent is how Shneidermans Refinement phase is covered by our system.
A similar agent-human dialog can be used to find the right spot in the hierarchy for a specific topic the user wants to either find information about or add information to.
The main challenge in creating a search tool like this is, in addition
to building an index as already described, to create a system for generating
questions based on the hierarchic structure of the information and the
information itself. The questions asked must be formulated in a way making
it is easy to see the difference between the alternatives.
For both the agent-supported and the form-based search, clicking on
a Dewey classification code in the listings should bring up the Web pages
that are indexed with that particular code. If very specific (extended)
Dewey classification codes are chosen, this will be a very efficient way
to find information closely related to the subject the user is interested
in.
The minimum information needed as input to the system is the URL of the Web page someone wants to have classified and indexed. Given this URL, we can check that the page really can not be found in the index already. If so, we can instruct a retrieval agent to go to the page and collect information about that page as normal. When this information reaches the classification and indexing agency, it should be directed to an express line, so that it can be processed and included in the index quickly.
When creating a Web page for allowing submitting Web pages to the index,
we should take advantage of the opportunity to collect meta information.
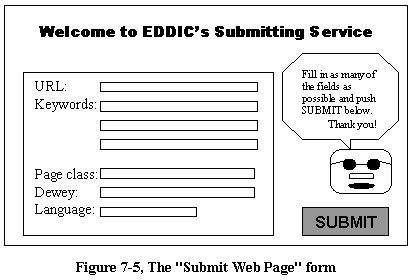
This can be done by designing a good Submit Web page on-line form, as
shown in Figure 7-5, where the user that submits the page can include meta
information. The user can use any keywords he or she likes, while the other
fields must be compatible with the EDDIC code system. Some of the fields
can be multiple choice or menu-like.
If the user fills in all the fields correctly, the classification of the Web page can be done quickly. The user can find the correct codes by reading explanations and navigating to the correct place in the Dewey hierarchy as described earlier in Chapter 7. The information from the form should be stored with the URL as the key, later to be joined with the information gathered by the agents. Using this, the human classification personnel can quickly check that the page actually is what the submitter claims it to be, and put the page in the correct spot in the hierarchy and with the best keywords.
The user may also fill in only the URL field and press the Submit-button.
In this case the classification may require a bit more human work, and
may take a bit longer to perform. This will encourage people to supply
as much meta information as they possibly can about their page when submitting
it for indexing.
If we want our agents to vary the way they act in accordance with the varying needs of the users, we need a way for the agents to identify the different users. When the agent knows what user or at least what kind of user it is to assist, it can retrieve the correct set of rules for behavior and follow these rules in its work. However, for the vast majority of the users an Internet search tool is something they want to pop up on their screen ready to be used without any further ado. This means we can not base our user identification on any user name + password login. It is also a matter of privacy to be able to search for information without having to identify yourself.
This means we have two choices:
Within this profile we need to store information about what Dewey codes and what kind of Web pages the person seems to repeatedly search in and for, what keywords most often occur on the pages the person actually follows the links to, what languages are preferred and so on. This information can, when it becomes comprehensive enough, be used to guide the agent in its work, ranking and sorting the hits, so that fewer questions needs to be asked to the user.
Both documents and queries can, in our system, be represented as weighted vectors, where each keyword or field code corresponds to one position in the vector. Documents from the search scope part of the index are ranked according to a normalized inner product between the query vector and the documents vectors. The user profile can be used to give certain keywords and field codes extra weight. Not all the query parameters need to be present in the document in order for the document to be retrieved. Likewise, a document that has many instances of a keyword or field with heavy weighting might be ranked higher than a document with few instances of several of the other query parameters. This is based on theory found in [Salton, 1989] and Chapter 5.2.
- Researcher : Someone who is using the Web to find research papers, calls for papers, technical journals, reports about university activities and so on. The rules give high priority to pages from educational and research institutions, commercial sites with the word research somewhere in the URL and pages with keywords like research, CFP, conference, university, ph.d, paper, report and so on.
- News reader : Someone who is looking for the latest news. The rules give priority to pages that very recently have been indexed, pages with the Breaking news page class code, pages from news sites and similar. The agent may also look at the users address and concentrate on providing news from the same part of the world as the user, since most available news is not of global interest.
- Child : Someone young who is looking for pages for children. The agents will only list pages that are classified to be made for children, and definitely remove all pages containing adult material from the listings.
Whether the profile model or the role model is chosen, the result should
be that the user feels more at home when using the search tool, since it
seems as if the agent knows a (little) bit about the user. Some roles
may give the user a faster and in other ways higher quality search access,
and may require special agreements and/or paid subscription to get access
to.